Final GSoC Blog - Polyglot
Looking back at Polyglot’s Development this Summer
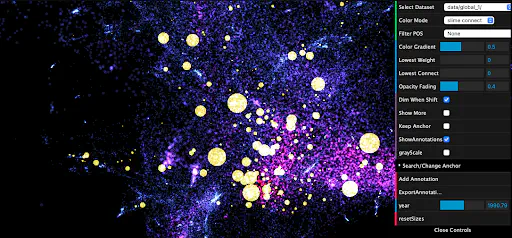
As I send in my final work submission for the final GSoC evaluation, I’m excited to share with you the progress we’ve made this summer (and future plans for Polyglot!). You can view the repository and web app here: https://polyphyhub.github.io/PolyGlot/. As a quick reminder of the project, we sought to extend the Polyglot web app, as developed by Hongwei (Henry) Zhou. For context, the web app follows this methodology:
Given a set of words, use an embedding model (such as Word2Vec, BERT, etc.) to generate a set of high dimensional points associated with each word.
Use a dimensionality reduction method (such as UMAP) to reduce the dimensionality of each word-vector point to 3 dimensions
Use the novel MCPM (Monte Carlo Physarum Machine) to compute the similarities between a set of anchor points and the rest of the point cloud. You could use any similarity metric here, too, such as the Euclidean distance.
The web app then displays the point cloud of 3-dimensional embeddings, but uses coloring to indicate the level of MCPM similarity each word has with the anchor point (e.g, if the anchor point is the word “dog”, the rest of the point cloud is colored such that words identified as similar to “dog” by the MCPM metric are brighter, whereas dissimilar words are darker.
The main results since the last blog are summarized as follows:
Novel timeline feature in which users can track the importance of certain words over time by watching the change in size of points (computes the IF-IDF metric for a word across all documents in a given year). Uses linear interpolation for years which do not have an explicit importance score.
An industrial collaboration with UK startup Lautonomy, where we have pre-processed and entered their data into Polyglot. Pre-processing consisted of first computing a high dimensional embedding of their set of words using OpenAI’s CLIP model https://openai.com/research/clip and the CLIP-as-service Python package https://clip-as-service.jina.ai. Next, we used UMAP to reduce the dimensionality of these embeddings to 3D. We computed the Euclidean distance on this data (in place of MCPM metric). Finally, we formatted the data to enter into Polyglot.
Although the app has developed a lot over the summer, we are planning to continue working on Polyglot, particularly with respect to one of our original goals: to set up a pipeline from PolyPhy to Polyglot. Unfortunately, with PolyPhy undergoing refactoring this summer, we weren’t able to set this pipeline up. However, that is one of our goals for the next few months. We are also moving forward with the industrial collaboration with legal analytics startup Lautonomy. We hope to release an output together soon!
If you’re curious about Polyglot or are interesting in getting involved, please feel free to reach out to myself, Oskar Elek, and Jasmine Otto!