GPEC: An Open Emulation Platform to Evaluate GPU/ML Workloads on Erasure Coding Storage
Project Idea Description
- Topics: Storage Systems, Machine Learning, Erasure Coding
- Skills: C/C++, Python, PyTorch, Bash scripting, Linux, Erasure Coding, Machine Learning
- Difficulty: Hard
- Size: Large (350 hours)
- Mentors: Meng Wang (primary contact), John Bent
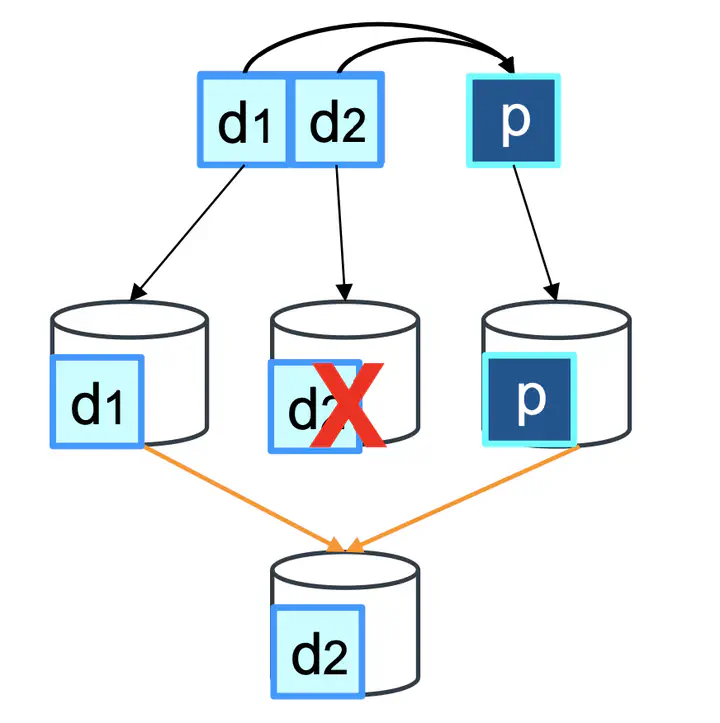
Large-scale data centers store immense amounts of user data across a multitude of disks, necessitating redundancy strategies like erasure coding (EC) to safeguard against disk failures. Numerous research efforts have sought to assess the performance and durability of various erasure coding approaches, including single-level erasure coding, locally recoverable coding, and multi-level erasure coding.
Despite its widespread adoption, a significant research gap exists regarding the performance of large-scale erasure-coded storage systems when exposed to machine learning (ML) workloads. While conventional practice often leans towards replication for enhanced performance, this project seeks to explore whether cost-effective erasure encoding can deliver comparable performance. In this context, several fundamental questions remain unanswered, including: Can a typical erasure-coded storage system deliver sufficient throughput for ML training tasks? Can an erasure-coded storage system maintain low-latency performance for ML training and inference workloads? How does disk failure and subsequent repair impact the throughput and latency of ML workloads? What influence do various erasure coding design choices, such as chunk placement strategies and repair methods, have on the aforementioned performance metrics?
To address these questions, the most straightforward approach would involve running ML workloads on large-scale erasure coded storage systems within HPC data centers. However, this presents challenges for researchers and students due to limited access to expensive GPUs and distributed storage systems, especially when dealing with large-scale evaluations. Consequently, there is a need for a cost-effective evaluation platform.
The objective of this project is to develop an open-source platform that facilitates cheap and reproducible evaluations of erasure-coded storage systems concerning ML workloads. This platform consists of two key components: GPU Emulator: This emulator is designed to simulate GPU performance for ML workloads. Development of the GPU emulator is near completion. EC Emulator: This emulator is designed to simulate the performance characteristics of erasure-coded storage systems. It is still in the exploratory phase and requires further development.
The student’s responsibilities will include documenting the GPU emulator, progressing the development of the EC emulator, and packaging the experiments to ensure easy reproducibility. It is anticipated that this platform will empower researchers and students to conduct cost-effective and reproducible evaluations of large-scale erasure-coded storage systems in the context of ML workloads.
Project Deliverable
- Build an EC emulator to emulate the performance characteristics of large-scale erasure-coded storage systems
- Incorporate the EC emulator into ML workloads and GPU emulator
- Conduct reproducible experiments to evaluate the performance of erasure-coded storage systems in the context of ML workloads
- Publish a Trovi artifact shared on Chameleon Cloud and a GitHub repository with open-source code
John Bent
Research Scientist, Los Alamos National Laboratory
John Bent is currently a research scientist at Los Alamos National Laboratory (LANL). He has researched, designed, and built storage and I/O systems all throughout his multi-decade career.
Meng Wang
PhD Student, University of Chicago
Meng Wang is a Ph.D. candidate in the Department of Computer Science at the University of Chicago. His research focuses on enhancing the performance and dependability of storage systems in cloud, HPC, and ML environments.